The Hidden Cost of Change: Lessons on Backward Compatibility from Building Platforms and APIs
Building platforms, APIs, and shared libraries isn’t just about clean code. It’s about not breaking people.
🧠 Backward Compatibility Is Harder Than It Looks
When you build platforms, APIs, or shared libraries, your users aren’t just “other teams” — they’re often hundreds of services, workflows, or people you’ve never met. Every small change can have a big, invisible blast radius.
I used to think breaking changes meant changing an endpoint or removing a field. But over time, I learned that backward compatibility goes much deeper than that — it includes performance, side channels, debug output, even the order of keys in a JSON string.
This post is about the things we broke without meaning to, what we learned the hard way, and how to design systems that evolve without surprising your users.
🚧 The Usual Advice (That Still Matters)
When people talk about backward compatibility, the usual advice sounds simple:
- Use versioning.
- Make only additive changes.
- Introduce new behaviors as opt-in.
- Be tolerant when reading inputs, strict when writing outputs.
This advice covers the basics — but it doesn’t protect you from the real-world surprises we’ll see next.
🔥 Real Stories: Where We Broke Things (And Why)
📚 Parsing Error Messages
We had an API that returned clear error codes and messages like:
Error: not allowed to see object “xxx”
We thought clients would use the code to decide what to do. Instead, some teams started parsing the error string itself — pulling out the object name.
One day, we changed the wording slightly to improve clarity. It broke their applications.
🖥️ Humans-Only Debug Endpoints
We exposed an HTTP endpoint to show debug information. It was meant to be read by humans, in a browser.
We even documented clearly:
“This endpoint is for human viewing only. Output format is not stable for automation.”
Still, some teams built scripts that depended on the exact debug output. When we reformatted it for readability, their scripts failed.
Even when you say “do not depend on this”, someone eventually will.
🔒 Internal Systems Aren’t Always Internal
We had internal message queues used to pass messages between our own services. They were undocumented, private, and never intended for external use.
But someone found them. They built a prototype that read our internal messages — and that prototype grew into a production system.
When we changed the message format, their app broke. Technically, it was their fault. But in production, it became everyone’s problem.
🚀 Performance Is Part of the Contract
Backward compatibility isn’t just about what your system does. It’s also about how fast it does it.
We once made a small change to a low-level data retrieval API.
The functionality stayed the same — but the API got slightly slower.
That tiny performance degradation triggered cascading timeouts, retries, and failures across client applications.
Partial failures are incredibly hard to debug — and a slowdown can cause just as much damage as an outright break.
🧩 When Safe Changes Break Unsafe Clients
JSON doesn’t guarantee key order.
Still, when we refactored an API and reordered the keys in our JSON output, one team broke.
They had written a fragile parser that extracted a string based on fixed character positions in the JSON text.
When the order changed, so did the character offsets — and their application failed.
This raised a hard question: what level of backward compatibility should we guarantee?
In this case, it was the client’s fault for depending on unstable behavior.
We shouldn’t avoid safe improvements like this — but it shows how creative clients can be in unexpected ways.
🛠️ Feature Flags and Runtime Toggles: Handle With Care
One way to ship changes safely is to use feature flags or toggles.
They let us introduce new behavior gradually and selectively.
But toggles come with hidden dangers, especially when your system advertises capabilities to clients.
Imagine a system where the server sends this when a client connects:
1
2
3
{
"features": ["compression", "streaming", "bulk-fetch"]
}
The client reads this once during the handshake and configures itself based on the available features.
Now imagine that at runtime, an operator disables "bulk-fetch" through a feature flag.
The server stops accepting bulk-fetch operations immediately.
But the client still thinks the feature is available — because it cached the server’s original response.
This mismatch leads to hard-to-diagnose bugs:
- The server thinks “bulk-fetch is disabled.”
- The client keeps trying to use it.
Here’s a simple diagram to illustrate the mismatch:
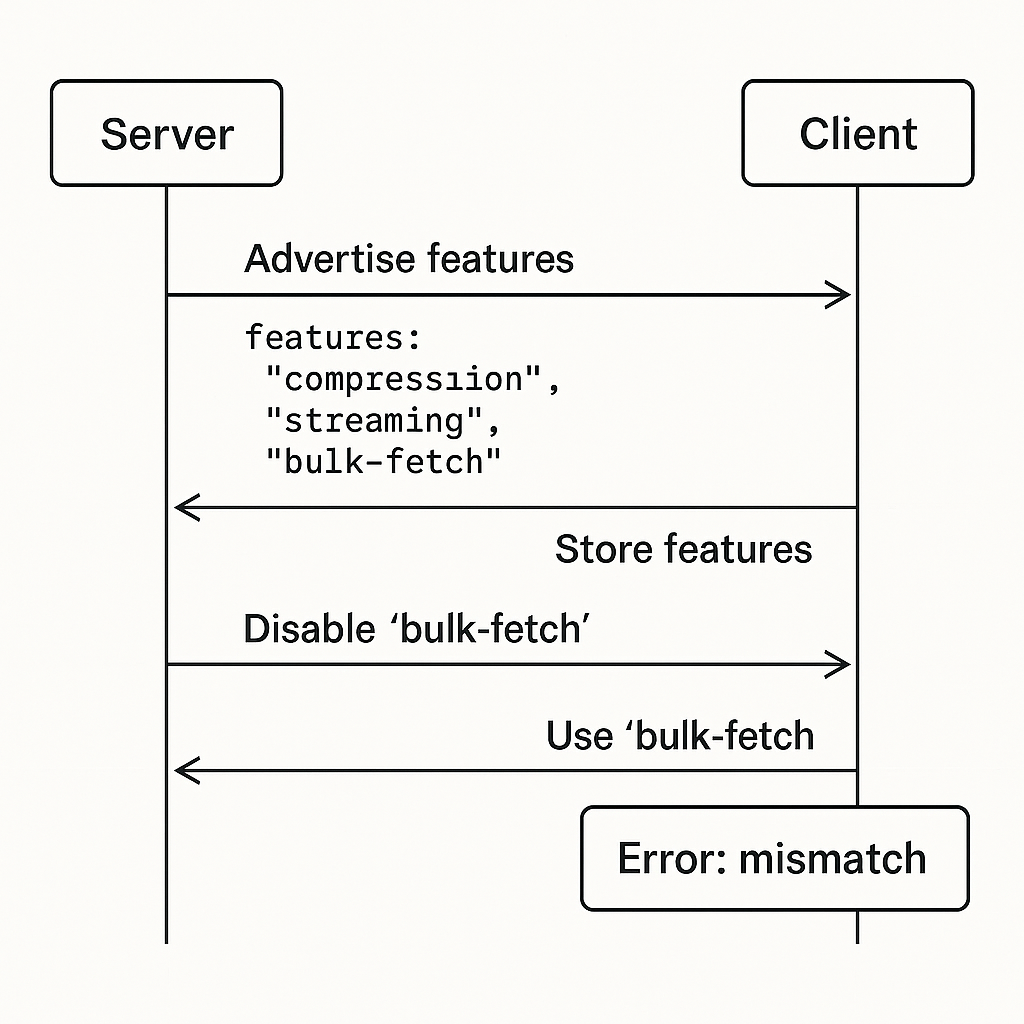
Lesson:
If features can be toggled dynamically, you need a way to re-negotiate capabilities at runtime, or ensure that changes don’t break existing conversations.
🕵️♂️ Hidden Traps in Backward Compatibility
🔓 “Public” Means Reachable, Not Documented
Anything visible can and will become a dependency.
If someone can see it, someone will eventually use it — no matter what you write in the documentation.
⚠️ Warning Signs of Accidental Dependencies
- Easy to scrape: People love easy shortcuts.
- No better alternative: If it’s the only way, they’ll take it.
- Faster or simpler than official APIs: Teams under time pressure will use whatever works.
🛡️ How to Harden Internal Things
If you don’t want others to depend on something:
- Require authentication or special access.
- Add headers or tags clearly marking the response as internal-only.
- Serve internal-only endpoints from separate domains or separate ports.
The harder it is to depend on something accidentally, the safer you are.
🧹 When Breaking Changes Are Necessary
Sometimes breaking changes are unavoidable — for example:
- Security vulnerabilities.
- Major architectural changes.
- Cleaning up technical debt.
When you must break something:
- Communicate early, often, and clearly.
- Offer dual-stack: old and new versions running side-by-side for a while.
- Add deprecation warnings in responses, headers, or logs to alert users.
The goal is never “no breakage.”
The goal is “no surprises.”
🛠️ Building a Culture of Compatibility
Backward compatibility isn’t just a checklist.
It’s a mindset.
- Think about how people might depend on you — even in ways you didn’t intend.
- Design systems assuming that every visible thing might eventually become a contract.
- Celebrate engineers who raise compatibility concerns during design reviews.
Backward compatibility is about empathy.
It’s about remembering that someone else, somewhere, is relying on you.
✅ Closing Thoughts
We don’t just build software for ourselves.
We build it for everyone who will depend on it — today, tomorrow, and years from now.
The best platforms aren’t just powerful.
They’re trustworthy.